Recently, the College of Chemistry and Molecular Engineering, in collaboration with the Computer Center, School of Computer Science, and Yuanpei College, has introduced SUPERChem. This new benchmark targets a critical gap in evaluating Large Language Models (LLMs): the lack of complex, multimodal, and process-oriented assessment in chemistry. SUPERChem establishes a systematic framework to rigorously evaluate the chemical reasoning capabilities of LLMs, aiming to push the boundaries of AI evaluation in scientific domains.
——Background—
The release of DeepSeek-R1 has accelerated the shift toward "Deep Thinking" LLMs, moving their science applications from simple Q&A to complex reasoning tasks. However, current benchmarks lag behind. General science benchmarks are reaching saturation, while existing chemistry-specific tests remain focused on basic skills and cheminformatics, failing to systematically evaluate deep reasoning.
Chemistry education, spanning from Olympiad level to higher education, demands knowledge integration and complex, multi-step deduction, making it an ideal testbed for AI cognitive abilities. Creating high-quality benchmarks for this field requires blending abstract concepts with specific contexts to build progressive reasoning chains, a task that calls for substantial domain expertise.
Leveraging the strong academic foundation and problem‑solving experience of the top-tier chemistry students of Peking University the research team designed SUPERChem. By carefully curating and optimizing assessment materials, they have successfully bridged the gap in evaluating deep chemical reasoning.
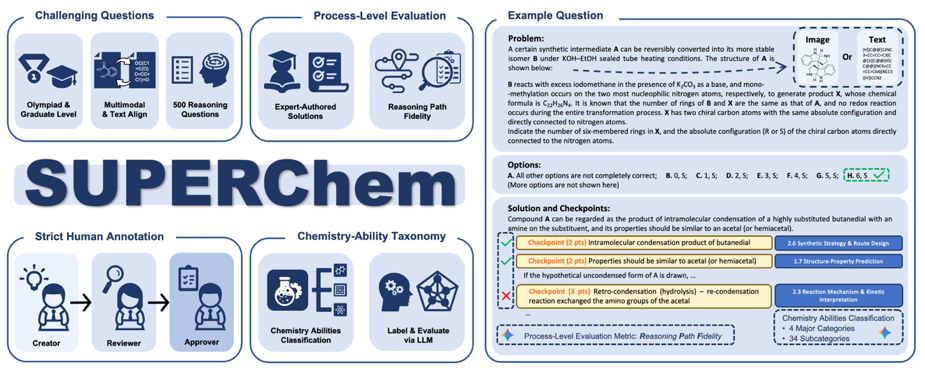
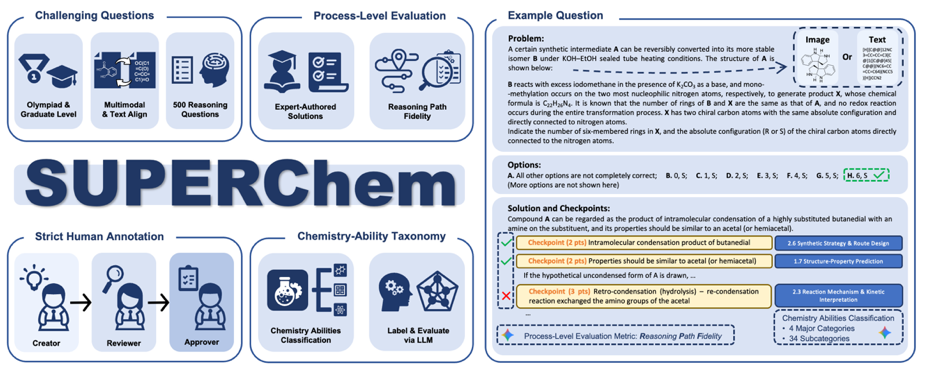
Figure 1. SUPERChem Overview and Sample Questions
—— Data Construction——
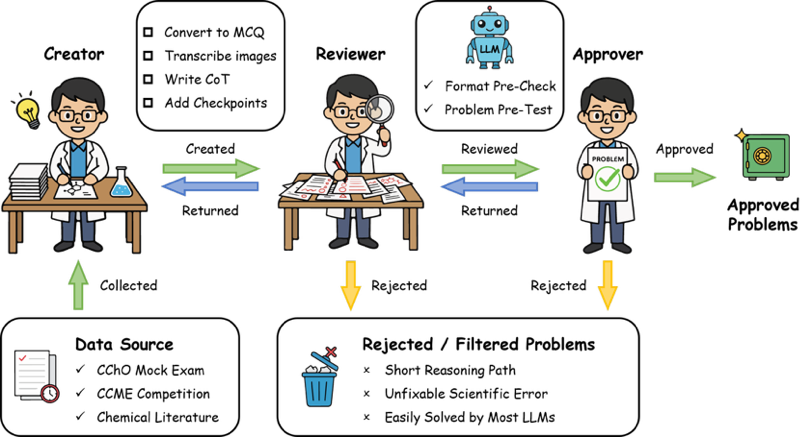
Figure 2. The Three-Stage Review Process of the SUPERChem Data Curation
The SUPERChem benchmark represents a collaborative effort by nearly 100 faculty members and students from chemistry and related disciplines at Peking University. The curation process involved a three-stage peer review. To prevent models from relying on memorized answers or reverse‑engineered solutions, questions were sourced from non‑public examinations and adapted scientific literature. Recognizing the multimodal nature of chemistry, the benchmark provides aligned datasets in both interleaved text-image and text-only formats, enabling analysis of visual modality's role in reasoning.
The initial release includes 500 expert-curated questions across four core domains: Structure and Properties, Reaction and Synthesis, Principles and Calculations, and Experimental Design and Analysis. To go beyond simple answer matching, SUPERChem introduces the Reasoning Path Fidelity (RPF) metric. Each question includes a detailed ground-truth solution with key reasoning checkpoints. By aligning the model’s Chain of Thought (CoT) with these expert annotations, RPF accurately evaluates whether the model possesses a genuine understanding of the underlying chemical logic.
—— Evaluation Results——
1. Frontier models approach second-year undergraduate levels, while reasoning consistency varies
Table 1: Performance of Frontier Models on SUPERChem
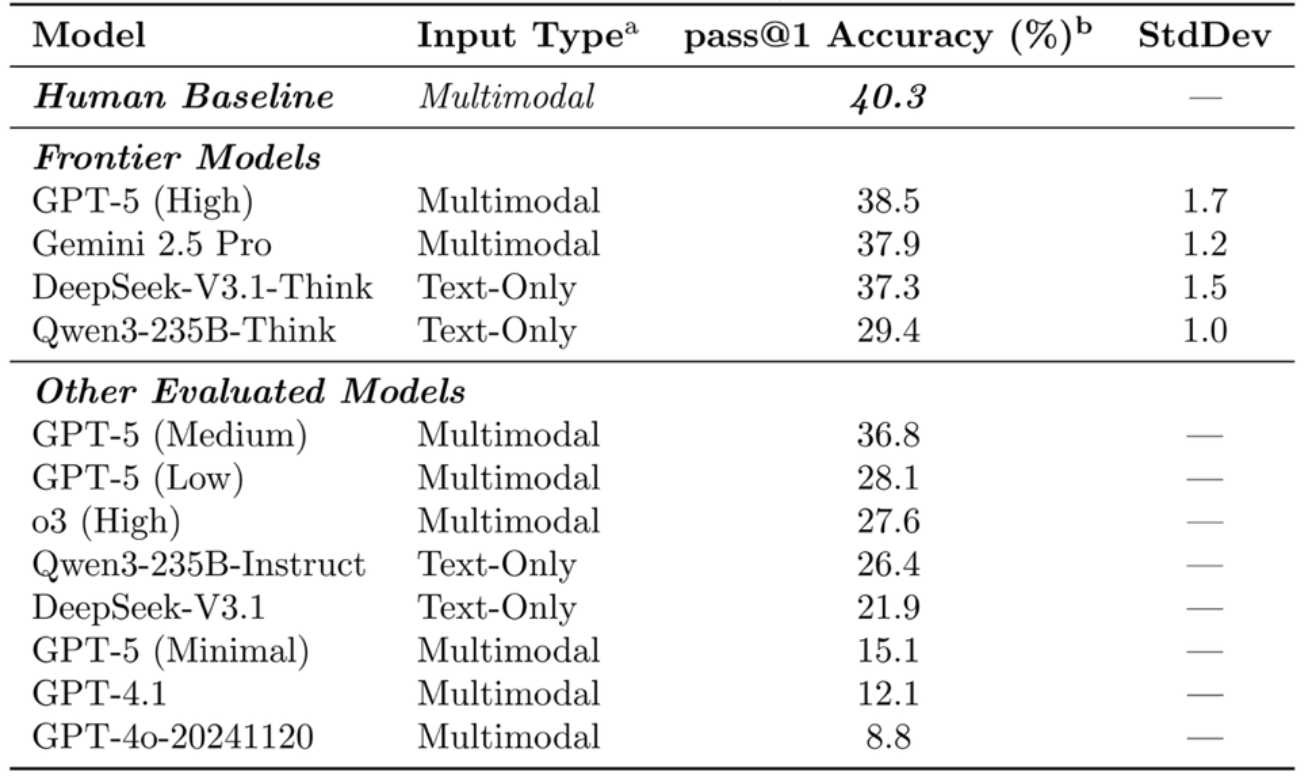
Benchmarking results highlight SUPERChem’s high difficulty and discriminative power. In a closed‑book test taken by second‑year chemistry majors at Peking University, human accuracy rate stood at 40.3%. The leading tested frontier model, GPT-5 (High), achieved a comparable 38.5%. This suggests that while top-tier models now rival undergraduate students in chemical reasoning, they have not yet surpassed trained human expertise.
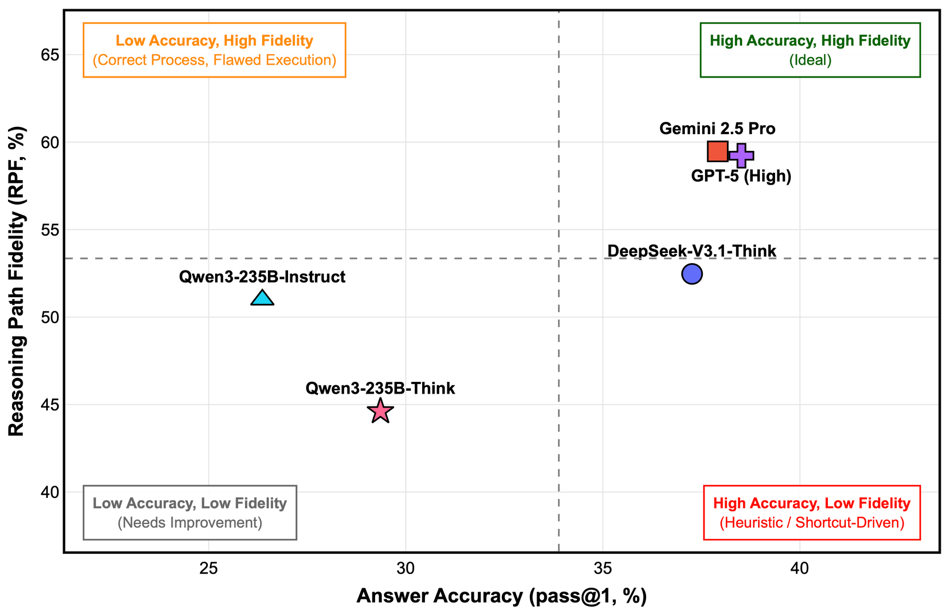
Figure 3. Relationship Between Accuracy and RPF in Frontier Models
Analysis using the Reasoning Path Fidelity (RPF) metric reveals notable differences in reasoning quality. While Gemini-2.5-Pro and GPT-5 (High) combined high accuracy with reasoning closely aligned to expert logic, DeepSeek-V3.1-Think scored lower on RPF despite similar accuracy, indicating a tendency to rely on heuristic shortcuts rather than rigorous deduction to reach conclusions.
2. The "Double-Edged Sword" of Multimodal Information
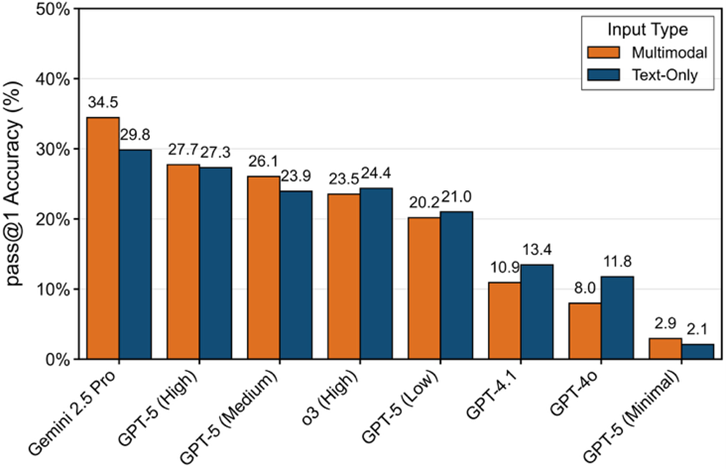
Figure 4: The Impact of Input Modality on Different Models
The effect of visual information depends on the model’s reasoning capability. For strong reasoners like Gemini-2.5-Pro, multimodal input boosts performance. However, for models with weaker reasoning baselines (e.g. GPT-4o), visual information often introduces distraction. This highlights the importance of pairing input types with a model’s cognitive strengths.
3. Analysis of Reasoning Breakpoints: Where do models fail?
To pinpoint failure modes, a First Failed Checkpoint analysis was conducted. Results show that frontier models struggle most in high-order reasoning tasks, particularly in predicting product structures, elucidating reaction mechanisms, and analyzing structure-activity relationships. These findings reveal critical limitations in how current LLMs handle tasks requiring a deep, mechanistic understanding of chemistry.
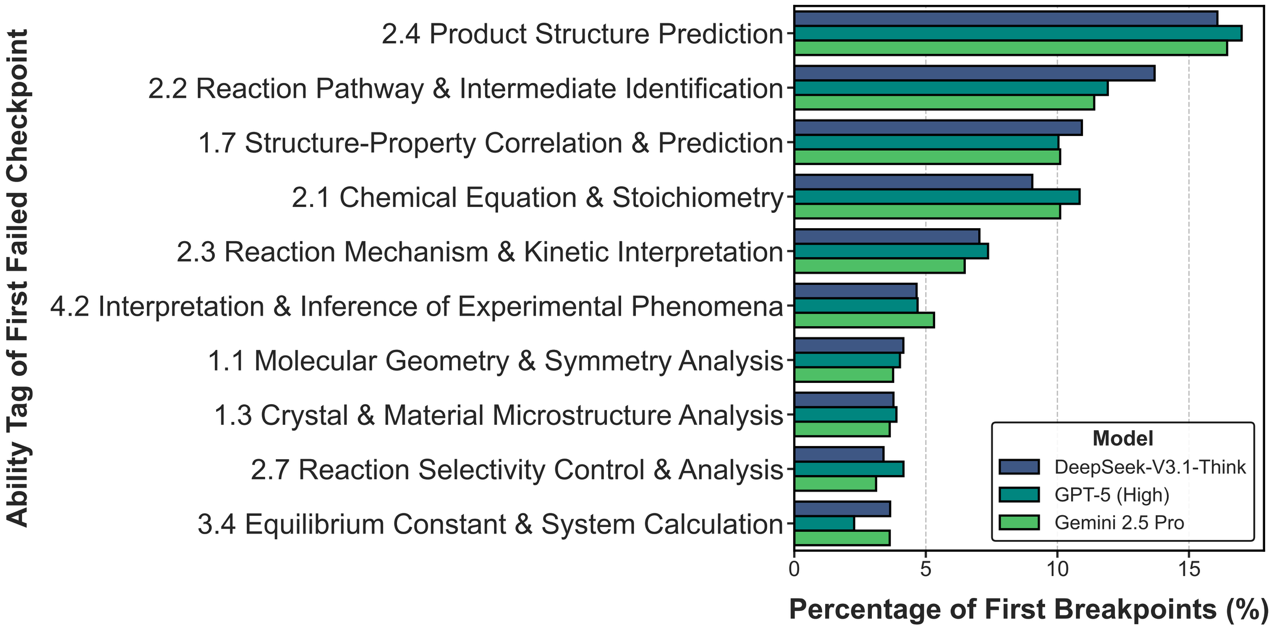
Figure 5. Distribution of Chemical Capabilities Associated with Reasoning Breakpoints
——Summary——
In summary, SUPERChem provides a comprehensive benchmark for evaluating the chemical reasoning of Large Language Models. The evaluation reveals that while today's frontier models possess foundational chemical knowledge, they struggle significantly with high-order reasoning tasks. These insights offer valuable direction for guiding future development of scientific AI systems.
——About the Team——
The SUPERChem project was led by Zehua Zhao, Zhixian Huang, Junren Li, and Siyu Lin from the College of Chemistry and Molecular Engineering and Yuanpei College at Peking University. The dataset was curated by a team of nearly 100 doctoral candidates and senior undergraduates, including medalists of International and Chinese Chemistry Olympiads. Baseline human performance was established through testing with 174 undergraduate students.
The project was guided by Profs. Jian Pei and Zhen Gao from the College of Chemistry and Molecular Engineering, Hao Ma from the Computer Center, and Tong Yang from the School of Computer Science. The team received support from the PKU Computer Center and the High-Performance Computing Platform. Data contributions were provided by organizations including Chemy, TAL, and Center of Mass, as well as by Professors Peng Zou, Jie Zheng, and other faculty members within the College of Chemistry and Molecular Engineering. Yang Gao and Tingting Long provided technical assistance to the project.
Project resources