




Recent Highlights
Contact us
张文彬课题组
地址:北京市海淀区成府路202号
北京大学化学与分子工程学院
邮编:100871
电话:010-62766876
电邮:wenbin@pku.edu.cn

请扫以上二维码关注我们课题组的公众号。
我们将定期推送组会每周精读和泛读文献介绍以及课题组的最近新闻!
--------------------------------------------
News
嗜热蛋白质能在较高温度下保持结构与功能的特点使其在工业应用中得以大显身手。为了规避实验上测量蛋白质熔点(Tm)的复杂流程,准确预测蛋白质的熔点已经成为研究的热点。以往方法主要依赖氨基酸组成、蛋白质理化性质以及宿主最佳生长温度(OGT)等条件来预测Tm值。然而,由于数据稀缺,这些方法在预测嗜热蛋白(Tm > 60 ℃)的Tm值时普遍表现欠佳。这也限制了嗜热蛋白质的系统挖掘与实际应用。
近期,北京大学张文彬教授课题组将蛋白质语言模型与深度神经网络框架结合,提出TmPred模型,大幅提升了嗜热蛋白质的Tm预测精度。TmPred模型包括三个模块:图卷积神经网络(GCN)、Graphormer模块和全连接层(FC)。TmPred采用了多模态的信息输入,使用ProtBERT蛋白质语言模型进行蛋白质的序列信息表征,使用残基接触图谱进行蛋白质的结构信息表征。多模态信息通过GCN进行融合,随后通过Graphormer模块引入注意力机制,得到的蛋白质特征嵌入向量通过FC层回归预测Tm值(图1a)。其中,Graphormer模块在Transformer的基础上引入了中心性编码(centrality encoding)和空间编码(spatial encoding),显著提升了模型对图结构数据的理解能力(图1b)。
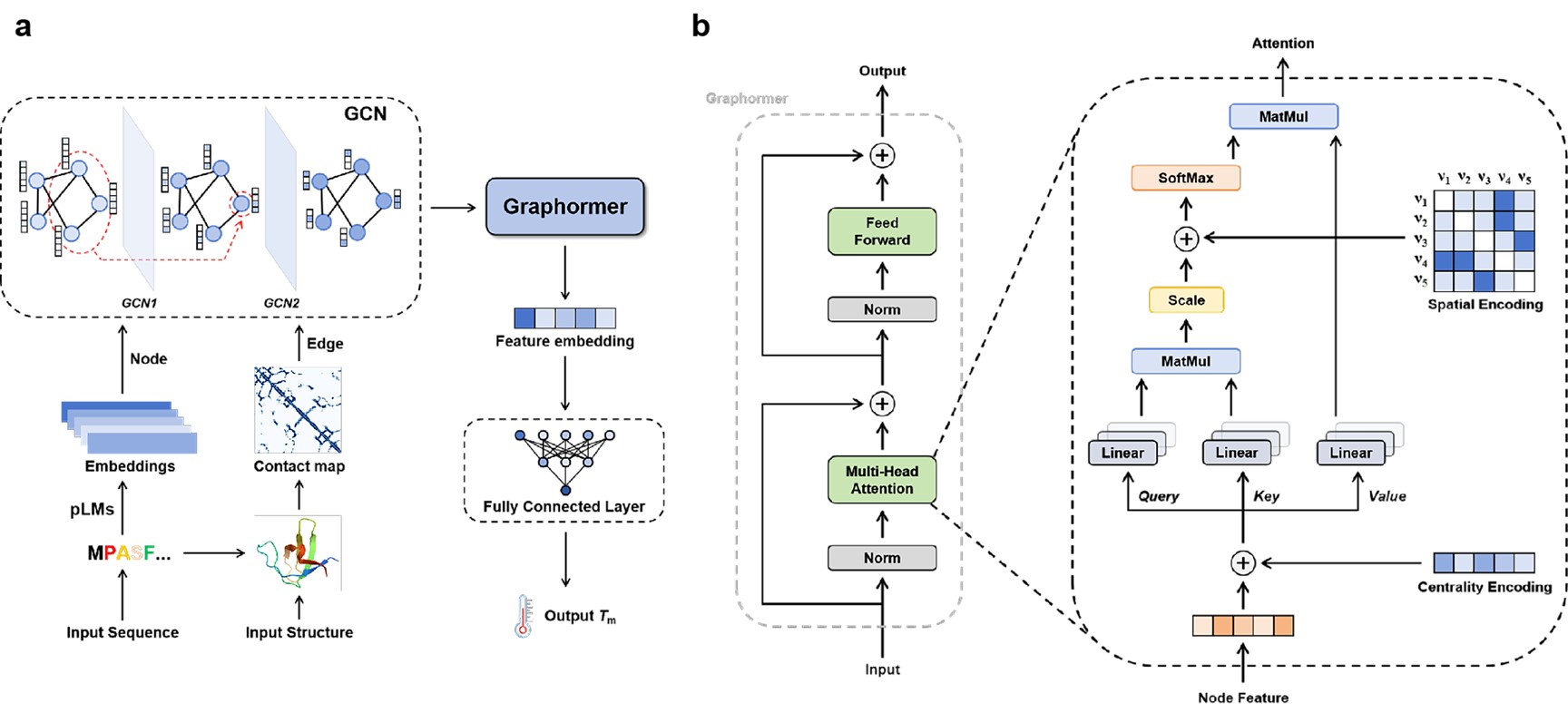
图1. TmPred的模型框架与Graphormer模块架构
相较此前的SOTA模型DeepTM,TmPred模型的预测性能有了大幅提升。在使用相同训练集与测试集的情况下,TmPred在测试集上预测结果的根均方误差(RMSE)相较DeepTM降低了19%,而Pearson相关系数(P)和决定系数(R2)则分别提升了15%与32%,且在各个温度区间,TmPred也展现出更窄的预测误差分布,表明TmPred具有良好的预测精度与预测稳定性(图2)。在真实的嗜热蛋白质盲测数据集上,TmPred相较于广泛应用的DeepTM、ProTstab2、DeepSTABp,也展现出更好的预测精度,从而验证了TmPred具有良好的可泛化性。
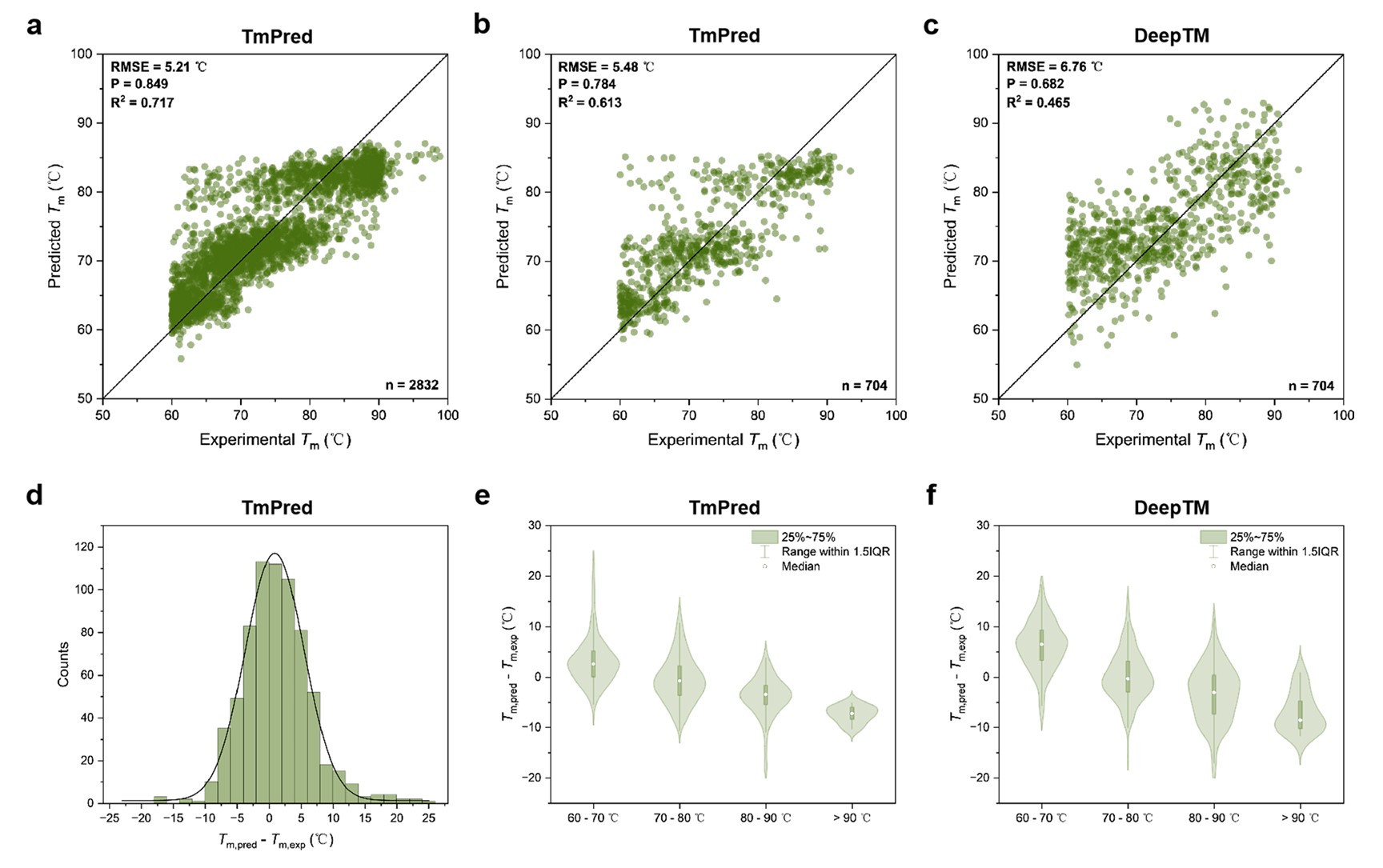
图2. TmPred与DeepTM的预测性能对比
随后,研究者对TmPred进行了系统的消融实验,从而解释了各个部分的作用。首先是TmPred整体架构的消融实验,通过逐步移除GCN模块、Graphormer模块,以及同时移除两个关键模块,模型的预测性能逐步下降,证明TmPred模型中的GCN模块和Graphormer模型缺一不可。随后是对Graphormer模块中引入的两个结构性质编码的消融实验,保持GCN模块和FC模块不变,将Graphormer模块替换成Transformer后,模型的预测性能显著下降,随后逐步向其中引入中心性编码和结构编码,模型的预测性能逐步提升,从而证明了Graphormer中两个特殊编码的重要性(图3)。
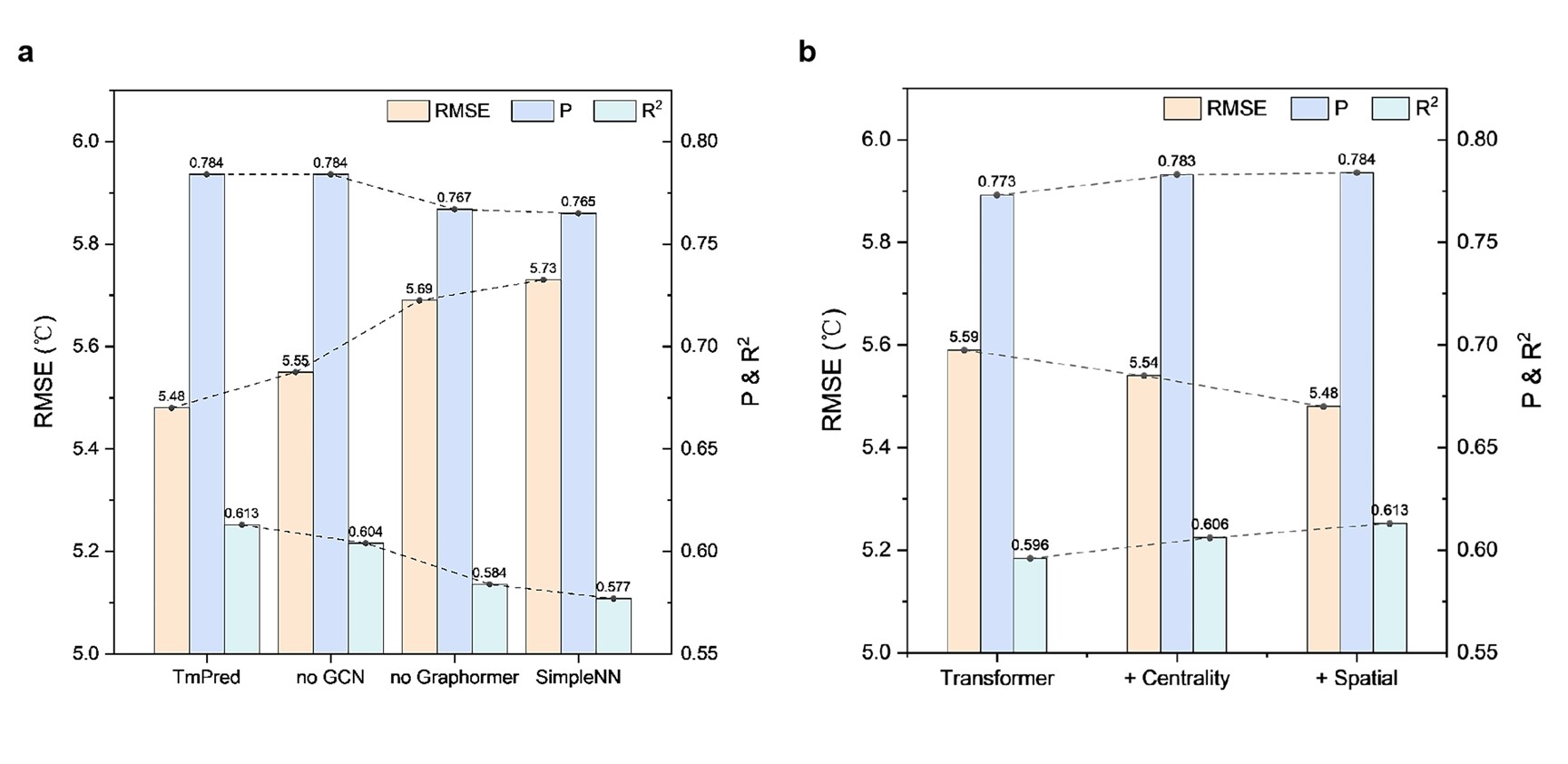
图3. TmPred模型与Graphormer模块的消融实验
综上所述,研究者结合蛋白质语言模型和深度神经网络提出了TmPred模型,通过对蛋白质进行多模态的信息表征,实现了嗜热蛋白质Tm的准确预测,并通过系统性的消融实验证明了TmPred框架设计的合理性。TmPred为嗜热蛋白质的研究提供了一个有力的工具。
该研究以“Enhancing Thermophilic Protein Melting Point Prediction with Protein Language Models and Deep Learning”为题,近期受邀发表于Chinese Journal of Polymer Science的“AI for Polymers”专刊,通讯作者为北京大学张文彬教授,第一作者为北京大学博士生江豪。北京大学硕士生张恭博,博士生王宇翔,博士生蒋冯逸,硕士生张宏宇,博士生聂志伟,以及北京大学深研院信息工程学院的袁粒教授与陈杰教授也共同协助了本研究。该工作得到国家自然科学基金委、国家重点研发计划、北京分子科学国家研究中心的大力支持。